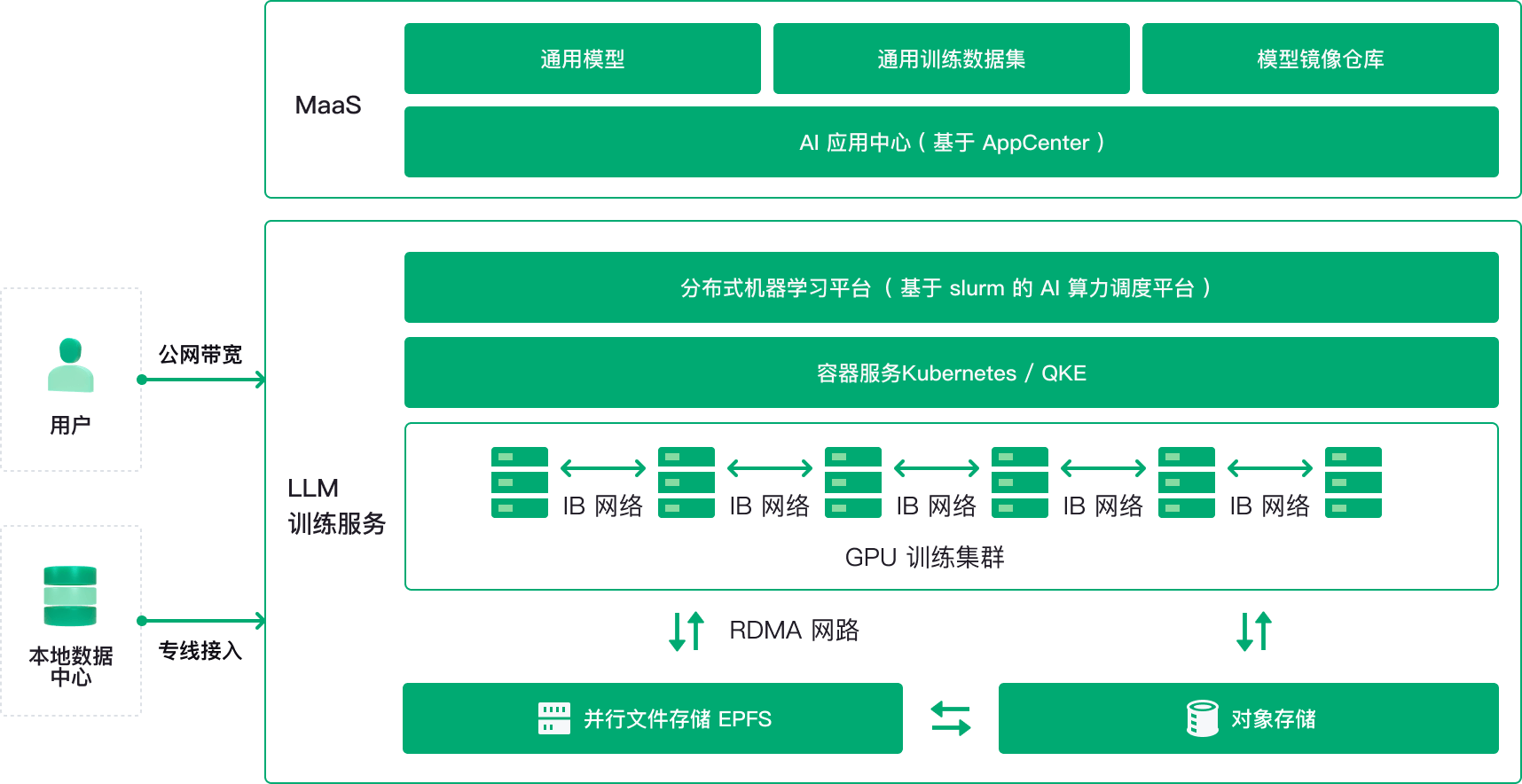
产品优势

极致算力
8 张 NVIDIA 数据中心卡,单机 NVSwitch 架构,结合高性能 CPU 为您提供强劲算力。

极高网络性能
基于 Mellanox HDR InfiniBand 解决方案,支持 InfiniBand 无限带宽技术,具有极高的吞吐量和极低的延迟。

完善配套服务
服务器本地 NVME 存储,支持挂载全闪并行文件存储 ,独享互联网出口带宽。

弹性扩容
根据您的业务增长,可不间断业务弹性增加云上 AI 算力资源。

深度学习环境集成
预置镜像集成 CUDA、Python、NCCL#、PyCharm, Jupyter 及 TensorFlow、Keras、PyTorch、Caffe、MXNet 等深度学习框架。

高端专属服务
1v1 专属管家式服务,保障您的业务持久稳定运行。