基石智算CoresHub 全面升级了模型推理服务!用户可在魔搭、huggingface 等下载模型到基石智算,通过模型推理服务进行一键部署推理服务,并对外提供 API 能力,也可经过基石智算的模型调优进行二次训练后再部署。
推理过程中可以根据业务的并发量,进行推理服务的弹性扩缩容,提高业务运行效率的同时,节省算力成本。
以下是通过模型推理服务一键部署模型的详细步骤,以魔搭下载的模型为例:
一、从魔搭下载模型到文件存储
1. 创建存储目录。
2. 创建一个用于传数据的无卡启动实例,挂载文件存储。
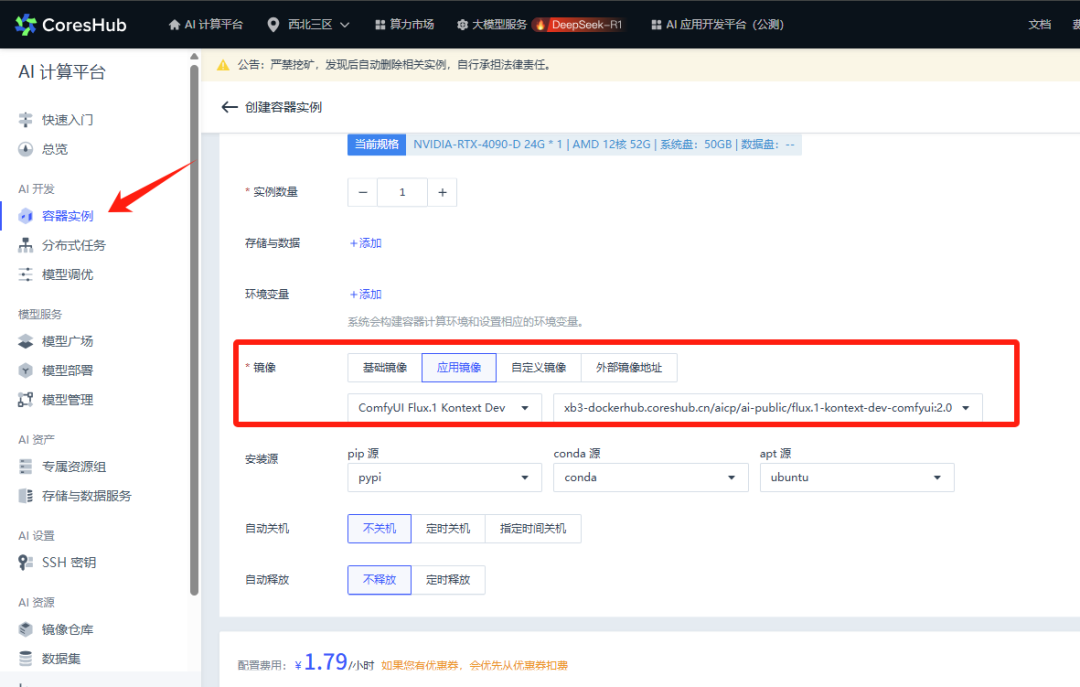
3. 在 Web 连接窗口中输入如下命令:
进入文件存储中
# cd epfs
安装 git-lfs 的软件包
# apt install git-lfs
4. 查看魔搭中的“模型文件—模型下载—下载”命令,使用 Git 下载
在 Web 连接中继续执行以下步骤:
# git lfs install
# git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B.git
二、模型部署
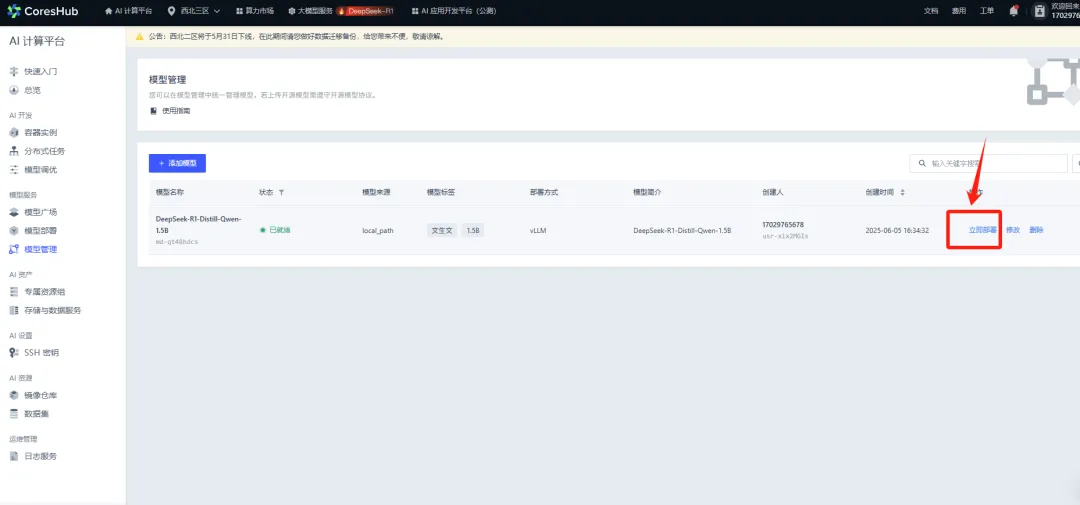
1. 到“模型管理”添加模型。
选择已下载的模型。
输入模型名称等信息,选择部署方式。
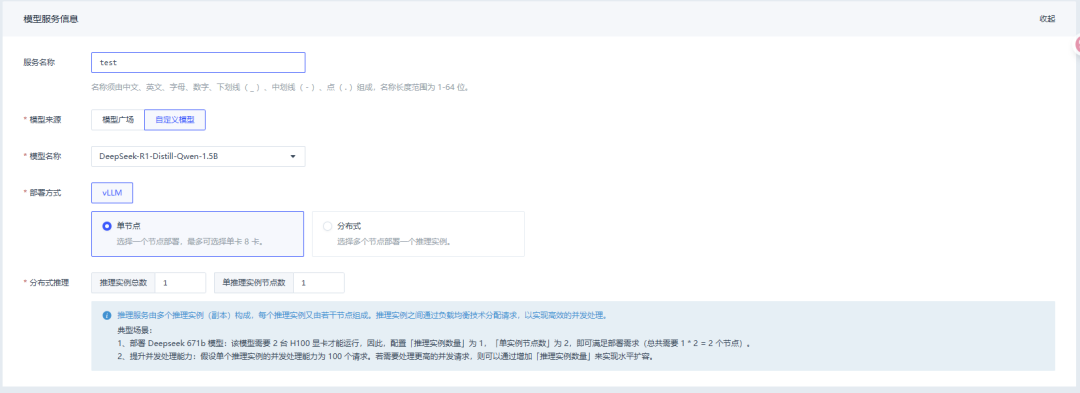
2. 部署模型
选择部署方式,支持单节点和多节点部署。
选择资源类型。
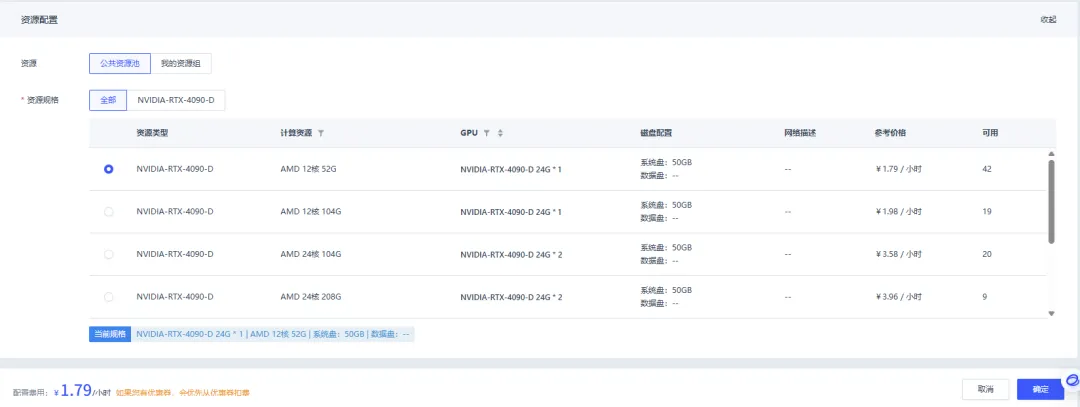
部署成功后,点击服务 ID 即可查看服务信息、服务监控、服务日志。
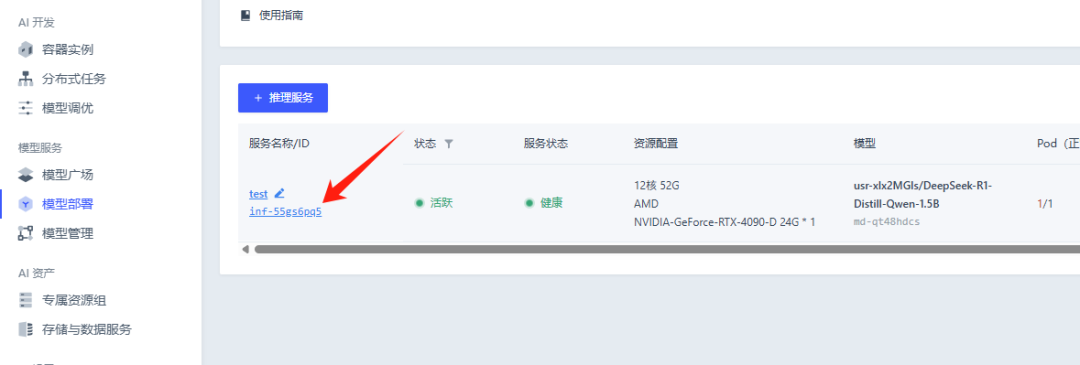
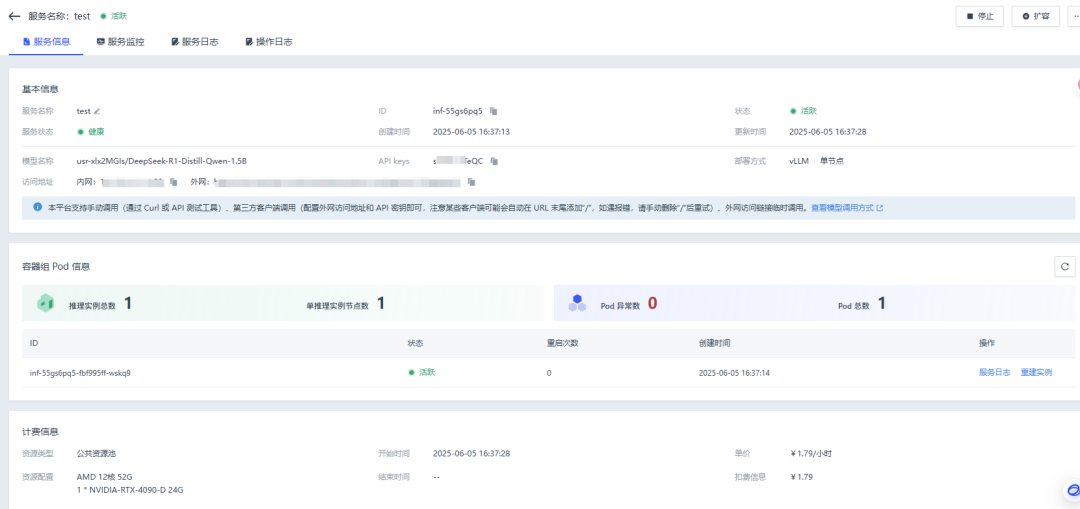
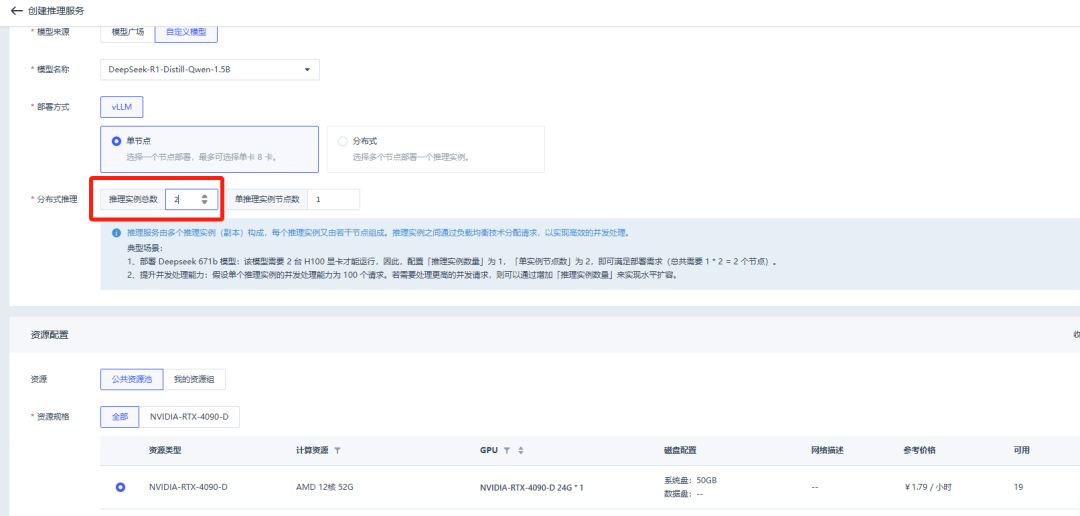
3. 支持扩容
当推理服务需要满足更高并发时,可以通过增加推理实例的数量,以满足业务的高并发需求。
假设 1 张 4090 可以满足 DeepSeek-R1-1.5B 最高 100 的并发数量,当业务并发超出 100,可以增加到 2 个 4090 的 1 卡实例进行模型部署。
三、 模型调用
1. 使用第三方客户端 Cherry Studio 调用为例,开启第三方工具,点击界面左下角的设置图标,选择模型服务 > 添加。
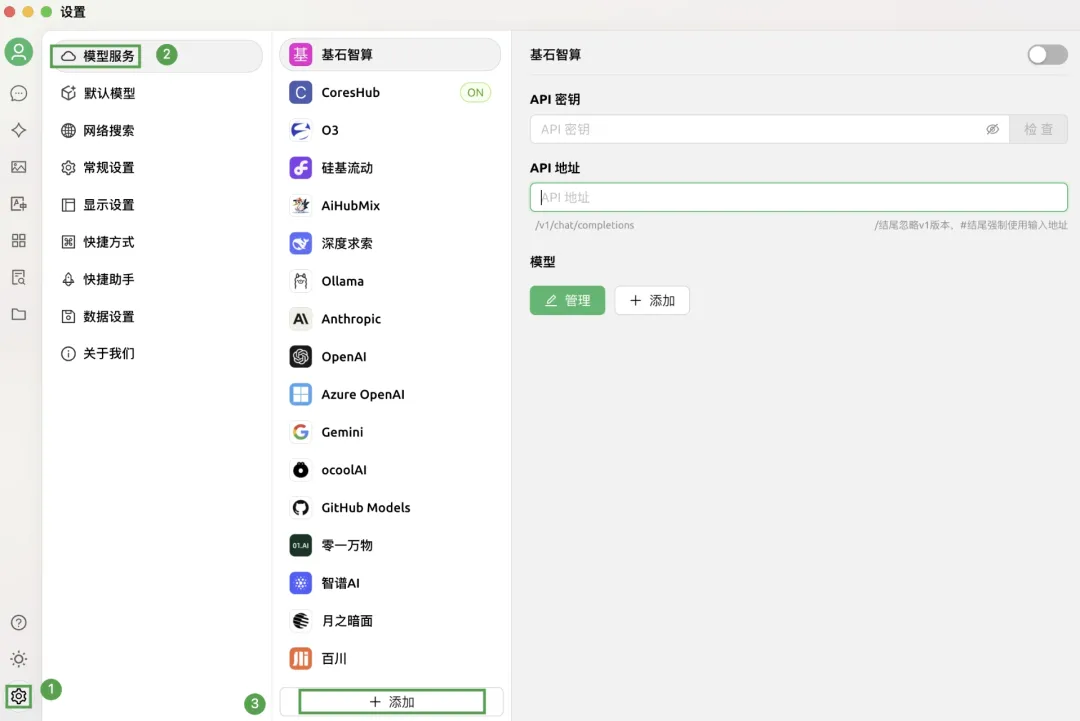
2. 在弹出添加提供商窗口中,配置各项参数,点击确定。

3. 新添加的提供商已显示在列,配置相应的 API 密钥和 API 路径,并点击管理,对应的密钥和 API 地址在服务信息中。
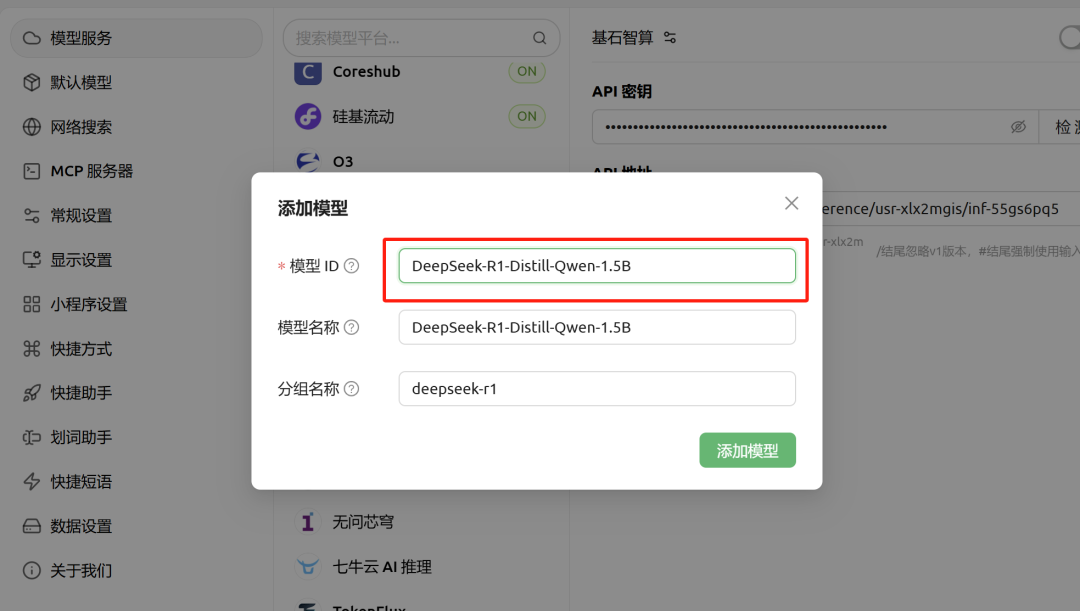
4. 配置模型名称。
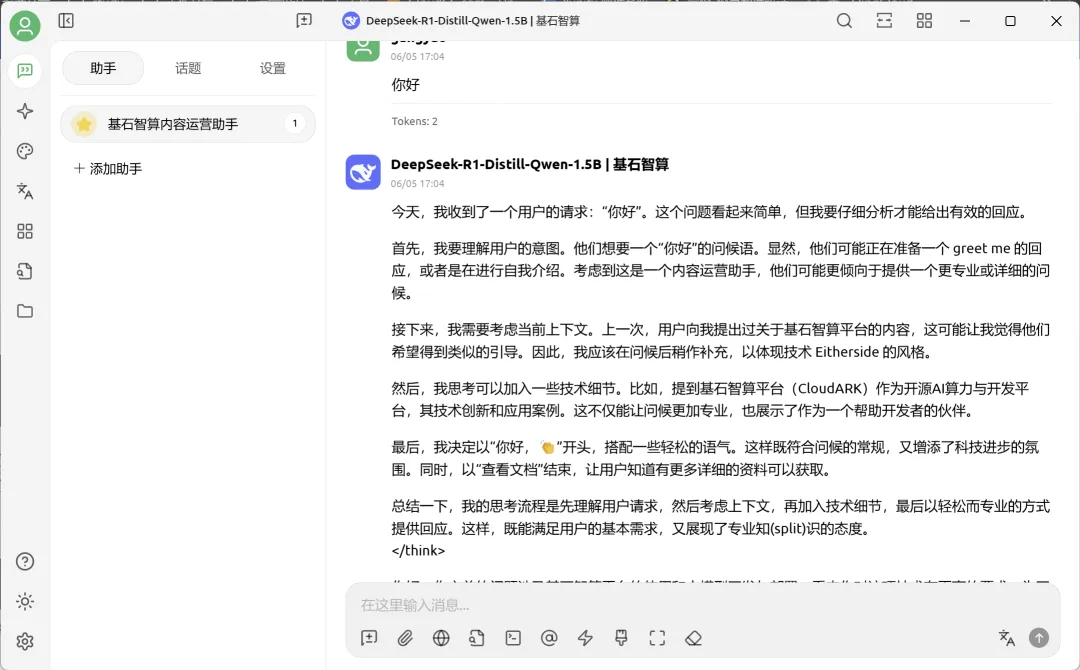
5. 在 CherryStudio 平台,点击左侧导航栏中的聊天助手,在对话框的顶部,切换已添加至平台上的模型,即可对话。
 分享
分享


