基石智算CoresHub 正式上线 DeepSeek-V3 满血模型,为用户带来全新的 AI 体验。DeepSeek-V3 模型以卓越的性能,助力各行业实现智能化升级。基石智算提供更灵活的调用方式,助力开发者快速构建高效智能应用。
DeepSeek-V3 模型亮点
DeepSeek-V3 模型在自然语言处理领域取得重大突破。它拥有庞大的预训练数据,对各种复杂语境理解精准,无论是日常对话、专业文档分析,还是创意写作,V3 模型都能快速生成高质量、逻辑清晰的回复。通过优化算法架构,它的运算速度大幅提升,响应时间更短,为实时交互场景提供有力支持。
DeepSeek-V3 在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平,接近当前表现最好的模型 Claude-3.5-Sonnet-1022。
● 长文本:在长文本测评中,DROP、FRAMES 和 LongBench v2 上,DeepSeek-V3 平均表现超越其他模型。
● 代码:DeepSeek-V3 在算法类代码场景(Codeforces),远远领先于市面上已有的全部非 o1类模型,并在工程类代码场景(SWE-Bench Verified)逼近 Claude-3.5-Sonnet-1022。
● 中文能力:DeepSeek-V3 与 Qwen 2.5-72B 在教育类测评 C-Eval 和代词消歧等评测集上表现相近,但在事实知识 C-SimpleQA 上更为领先。
DeepSeek-V3 与 R1 对比
DeepSeek-V3 作为一个通用 NLP 模型,适用于广泛的应用场景,能够高效处理各种文本生成、摘要和对话任务。DeepSeek-R1 则专注于逻辑推理和问题求解,借助强化学习优化推理能力,适用于推理密集型任务。
| 特性 | DeepSeek-V3 | DeepSeek-R1 |
| 架构 | 混合专家 (MoE) | 基于 V3,优化推理能力 |
| 参数规模 | 6710 亿 | 6710 亿 |
| 计算优化 | 每个Token激活的参数量为 370 亿参数 | 采用动态门控机制,适应推理任务 |
| 训练方法 | 结合负载均衡策略,优化专家分配 | 进一步增强专家调度,提高逻辑推理能力 |
| 推理能力 | 主要用于基于训练数据中编码的答案进行下一个词的预测 | 擅长复杂问题解决、逻辑和分步推理任务 |
| 内存和上下文处理 | 可处理多达 64,000 个输入标记,但在长时间交互中维护逻辑和上下文的能力相对较弱 | 特别擅长在长时间交互中维护逻辑和上下文 |
| 速度和效率 | 由于 MoE 架构,响应速度更快,更适合实时交互 | 生成响应时间较长,但提供更深入、更结构化的答案 |
| 应用场景 | 多功能 NLP 任务 | 复杂逻辑推理,多模态推理 |
| 价格 | 输入价格:0.002元 / 千 tokens输出价格:0.008 元/ 千 tokens | 输入价格:0.004 元/ 千 tokens输出价格:0.016 元/ 千 tokens |
DeepSeek-V3 调用方式
基石智算提供了兼容 OpenAI 接口规范的使用方式。支持多种调用方式,用户仅需创建 API 密钥,即可通过 AI 应用或第三方客户端完成对特定模型的调用访问。
具体使用方式参考:https://docs.coreshub.cn/console/big_model_server/call_scenario/
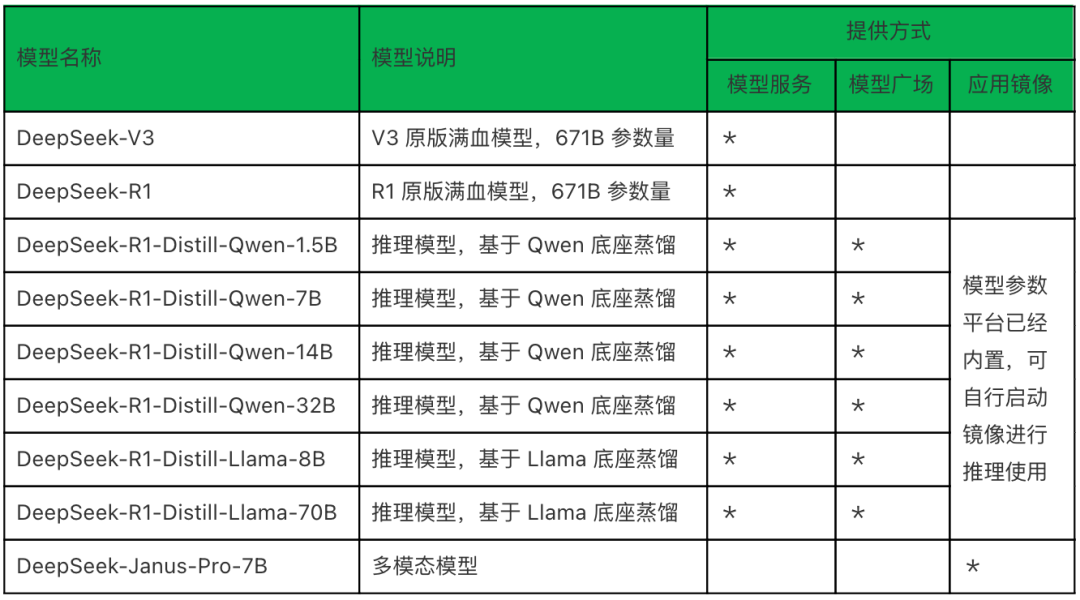
截至目前,基石智算已上线 DeepSeek 全系列模型,包括 V3、R1、Janus-Pro 等模型的满血、量化及蒸馏版本,并支持直接调用 API、云端一键部署、私有化部署等多种模型使用方式,满足不同用户对于数据安全、应用场景的个性化需求。
 分享
分享


